
¿Qué es el SEO y cómo aprovecharlo?
Thiago Granata
Cómo podemos aprovechar el SEO (Search Engine Optimization) para posicionar nuestro sitio web en las búsquedas de Google.
¿Cómo funciona la búsqueda de Google?
La búsqueda de Google es un proceso automatizado que funciona con unos ‘robots’ (rastreadores web) que están constantemente buscando páginas que añadir a su índice.
Este proceso de búsqueda consta de 3 etapas:
1. Rastreo
Esta etapa consiste de Google ‘descubriendo’ las URLs que aún no conoce (ya sea porque son nuevas o porque fueron actualizadas). Ahora, ¿cómo descubre Google estas URL? Esto lo logra siguiendo enlaces de páginas conocidas que lo lleven a nuevas ó también mediante el sitemap. Una vez que Google descubre una nueva página puede revisar que contiene, para ello se vuelve a utilizar el robot de Google. Es importante recalcar que al momento de revisar el contenido, Google renderiza la página, pero también ejecuta el código Javascript que encuentre, esto es útil ya que muchas veces nuestras aplicaciones generan contenido utilizando Javascript que de otra forma no sería rastreado.
Sin embargo, Google no siempre puede rastrear las páginas que descubrió. Ya sea porque nosotros mismos limitamos esa posibilidad mediante el uso de metaetiquetas o por especificaciones en el archivo robots.txt, porque nuestra página requiere de iniciar sesión o por otros problemas con los que se pueda encontrar el robot.
2. Indexación
Esta es la parte donde Google ‘interpreta’ el contenido de nuestro sitio web. En ella, se procesa todo el contenido textual, las etiquetas, atributos relevantes (como <title> alt), y multimedia (ímagenes, videos, etc).
Durante este proceso es cuando se determina si la página es un duplicado de otra o es la canónica. La página canónica es aquella cuyo contenido es más útil y completo, esa página es la que va aparecer en los resultados de búsqueda y la que se rastreará con mayor frecuencia. De todas formas, los duplicados son almacenados igualmente y presentados al usuario en determinados contextos, por ejemplo: una búsqueda muy especifica.
3. Publicación de resultados de busqueda.
Cuando un usuario hace una busqueda en Google, se busca en el índice páginas que coincidan con ella y devuelve los resultados de mayor calidad y más relevantes en base a la ubicación, idioma y dispositivo, entre otros.
También es interesante destacar que el formato del contenido que se va a mostrar, depende de la búsqueda hecha por el usuario. Es decir: si nosotros buscamos “gimnasio” es probable que obtengamos resultados de gimnasios cerca pero si buscamos “entrenamiento” probablemente nos aparezcan respuestas mucho más conceptuales.
Desde el punto de vista del desarrollo, esto está muy ligado a los datos estructurados. Un ejemplo de esto es cuando buscamos “Receta de Brownies”, ademas de mostrar los resultados de la manera tradicional Google va a analizar el contenido de las páginas en busca de aquellas que posean un Schema (en este caso de tipo Recipe) y va a presentar algunos de ellos de una forma diferente
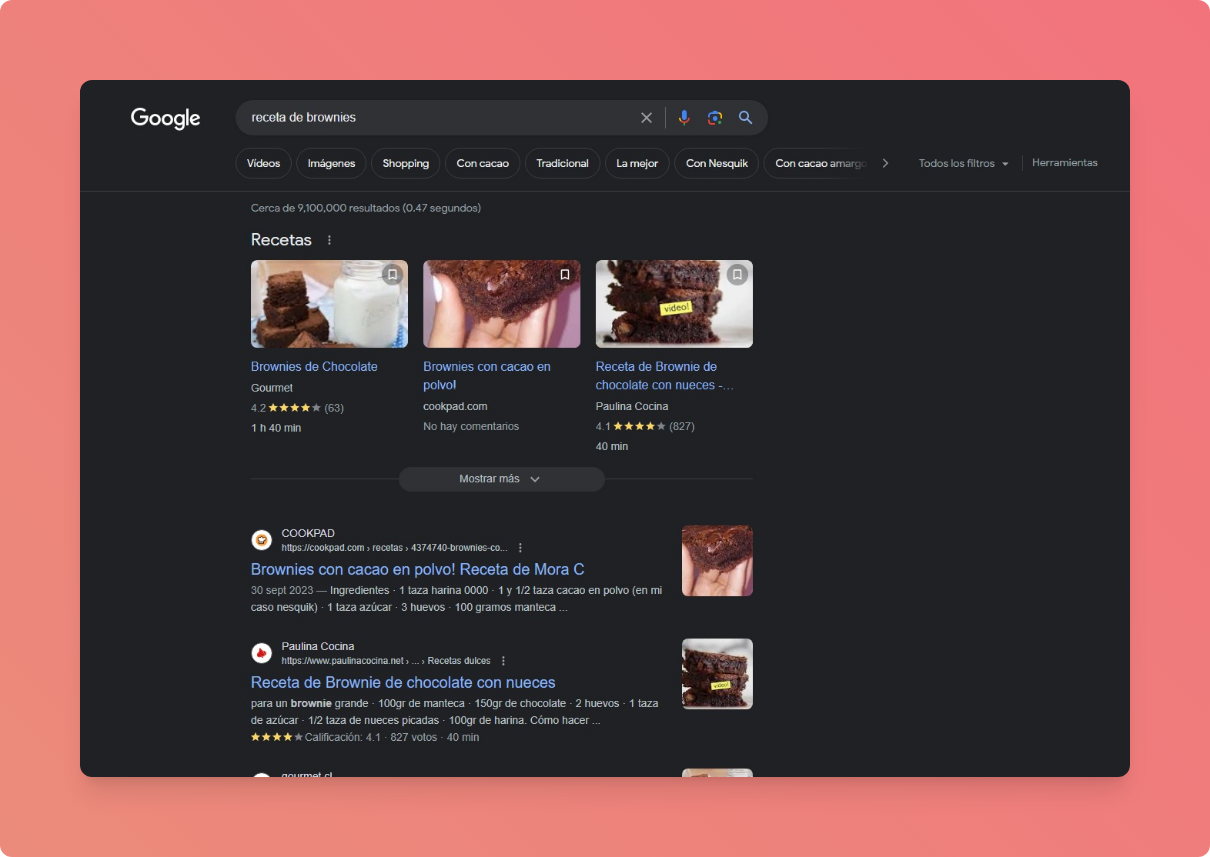
Cómo podemos observar en la imagen, aquellas páginas que tienen un Schema son presentadas de una forma mucho más destacable y que mejoran en general la presentación y visibilidad del contenido.
Como ayudar a Google a indexar nuestro contenido
Cómo desarrolladores, podemos ayudar a Google a que indexe nuestro contenido correctamente. La forma recomendada es creando un sitemap para nuestro sitio, un sitemap es un archivo que proporciona información de nuestro sitio web (páginas, videos, etc) usualmente escrito en XML.
Por ejemplo: esta es una parte del sitemap que generó @astrojs/sitemap para este sitio
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:news="http://www.google.com/schemas/sitemap-news/0.9" xmlns:xhtml="http://www.w3.org/1999/xhtml" xmlns:image="http://www.google.com/schemas/sitemap-image/1.1" xmlns:video="http://www.google.com/schemas/sitemap-video/1.1">
<url>
<loc>
https://tmgranata.com/
</loc>
</url>
<url>
<loc>
https://tmgranata.com/blog/
</loc>
</url>
</urlset>Los buscadores utilizan estos archivos para rastrear los sitios web de manera más eficiente. De todas formas, un sitemap no siempre es obligatorio pero puede ser de gran ayuda en ciertos casos (más información de sitemaps).
También es muy efectivo utilizar correctamente las etiquetas HTML <title> y <meta>. En general existen ciertas normas que nos pueden ayudar a ser más efectivos al utilizarlas:
- Elegir un titulo que describa con precisión el contenido de la página. El titulo debe ser breve pero descriptivo, que sea muy largo puede generar que Google termine mostrando solo una parte de él.
- Titulos únicos para cada página. De esta forma ayudamos a diferenciar páginas de otras
- Proveer un resumen preciso y único en la descripción de cada página
<meta name="description" content="(...)">
El uso del HTML semántico juega un rol importante para marcar una estructura jerárquica de nuestro contenido y si lo utilizamos de forma correcta vamos a mejorar la navegación por nuestro sitio. Por eso, tenemos que tener en consideración el uso apropiado de encabezados, enlaces, y secciones.
Para destacar, la optimización en general de nuestro sitio también es importante para el SEO. Optimizar las imágenes y videos, la adaptabilidad y el contenido va a generar una experiencia mucho más agradable para nuestros usuarios y por ende para los buscadores.
Como apliqué esto
Astro hace algunas de las cosas muy amenas gracias a las integraciones que posee.
Primero comencé por crear el sitemap, utilizando @astrojs/sitemap. Para ello, instalé el paquete y lo agregué como una integración
// astro.config.mjs
export default defineConfig({
integrations: [sitemap()],
(...)
});Adicionalmente, tenía que añadir el sitemap generado tanto al head del sitio como al archivo robots.txt
<!-- Layout.astro -->
<head>
<link rel="sitemap" href="/sitemap-index.xml" />
</head>// robots.txt
Sitemap: https://www.tmgranata.com/sitemap-index.xmlDespués, verifiqué mi dominio en Google Search Console con el fin de poder utilizar las herramientas que nos provee.
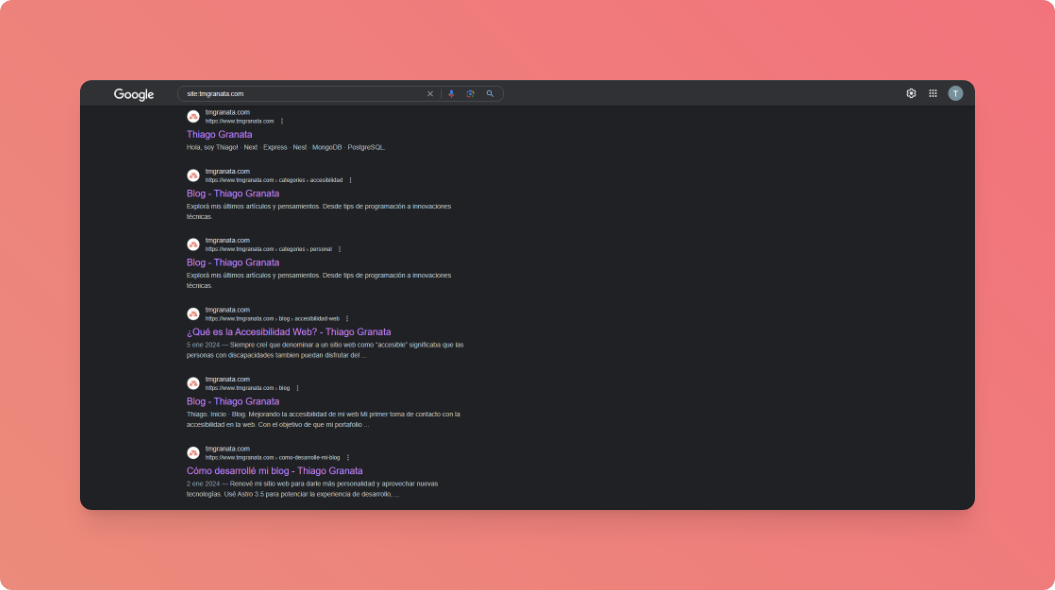
Uno de los problemas que tuve era que al buscar mi sitio mediante site:tmgranata.com los artículos y categorias no eran indexados por Google.
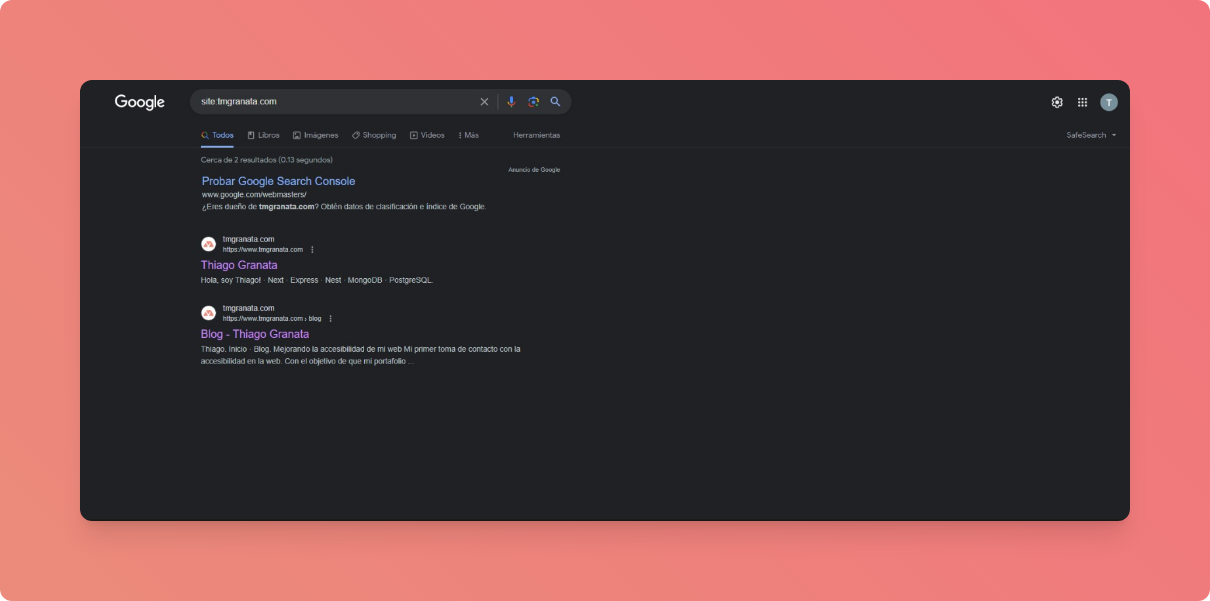
Para solucionar esto envié el sitemap generado mediante el search console. Esto hizo que Google descubra esas páginas, pero aún asi, no las indexaba (Discovered: Currently not indexed). Tras investigar un poco como podia resolver esto, me encontré con que podia solicitar manualmente la indexación de las páginas.
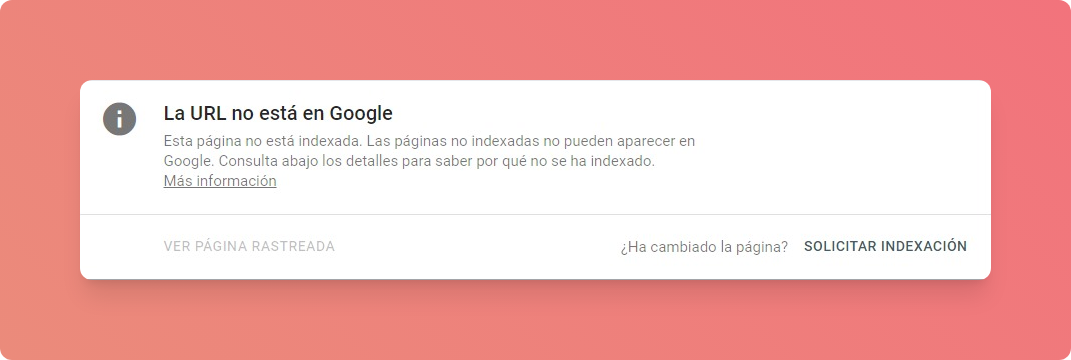
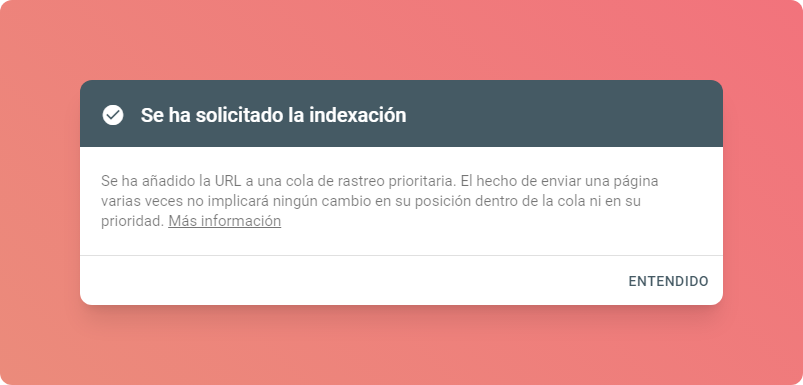
Si bien esto no es ideal ya que claramente me gustaría que Google indexe automáticamente mis páginas, es una forma de resolverlo hasta encontrar una solución definitiva al problema. Una vez enviadas todas las solicitudes de indexación quedaba esperar.
Despues de unas cuantas horas, Google indexó casi todas las URLS que había solicitado inspeccionar:
No podia faltar tratar con datos estructurados, así que agregué el schema de BlogPosting a los articulos en mi página. Para ello, tuve que usar JSON-LD (JSON for Linking Data) y simplemente “mapear” los atributos de Frontmatter a los que definia el schema de BlogPosting.
El resultado final en un articulo real se ve algo así:
<script type="application/ld+json" data-astro-exec>
{
"@context":"https://schema.org",
"@type":"BlogPosting",
"headline":"¿Qué es el SEO y cómo aprovecharlo?",
"description":"Que es el rastreo, indexación, sitemaps, datos estructurados y como aprovechar el SEO como desarrolladores para potenciar nuestros sitios webs",
"keywords":["accesibilidad","seo","astro","google","index","sitemaps"],
"author":{
"@type":"Person",
"name":"Thiago Granata",
"url":"https://tmgranata.com"
},
"datePublished":"2024-01-19"
}
</script>Si les interesa como pueden hacer esto utilizando Astro, hay un artículo que lo explica muy bien: Adding structured data to blog posts using Astro.
Como algo adicional, agregué un RSS Feed (Really Simple Syndication) que les permite a los usuarios “suscribirse” a una web y recibir el contenido actualizado de ella mediante programas diseñados para leer RSS.
Para agregar el feed, existe un paquete dentro de Astro que puede generarlo automáticamente (@astrojs/rss),
realicé las configuraciones necesarias y agregué el feed al footer del sitio. No obstante, RSS se escribe
en XML, por lo que si clickeamos el link vamos a previsualizar directamente el código:
<rss xmlns:atom="http://www.w3.org/2005/Atom" version="2.0">
<channel>
...
</channel>
</rss>Si bien esto no está mal (ya que la idea es que los usuarios consuman el contenido desde su lector preferido y no desde la fuente) podia ser extraño para ciertos usuarios, así que agregué un template de estilos al feed (pretty-feed-v3) para obtener un primer vistazo un poco más amigable.
Estilar el RSS Feed tiene algunas desventajas (como bien se detalla en el Github del template) pero considero que las ventajas son mayores.
Conclusiones
En el artículo detallamos como los desarrolladores podemos aprovechar el SEO para mejorar la visibilidad y el rendimiento de nuestros sitios, desde la teoria detras del proceso de búsqueda hasta la implementación práctica de buenas prácticas de SEO.
Personalmente, redactar este artículo me ayudó a comprender mucho mejor cómo funciona la búsqueda en los navegadores y también me permitió implementar mejoras significativas en mi propio sitio web.
Referencias
Categorias
- seo
- web